18 Module 5
Materials for March 21–April 1, 2022.
18.1 Introduction
What models have we looked at so far?
recapped linear regression + model matrices
linear mixed models (LMM)
- for when our observations aren’t independent due to some sort of grouping
generalized linear models (GLM)
- for situations where linear models don’t work because of the response type
What’s next?
generalized linear mixed models (GLMM)
- when we shouldn’t use LMMs because of the response
- and we shouldn’t use GLMs because of grouping/repeated measures in our data
generalized additive models (GAM)
- when we want even more flexibility in the relationships between our predictors and response.
18.2 GLMMs
18.2.1 What were mixed effects, again?
We call these mixed effect models because they mix fixed effects (the way you’re used to comparing the differences between treatments or effect of covariates) and random effects (generally experimental or observational blocks within which observations are grouped).
These types of models can be especially useful for people working with psychological, economic, social and ecological data.
18.2.2 Pros and cons of generalized linear mixed models
Pros
Powerful class of models that combine the characteristics of generalized linear models (GLMs) and linear mixed models (LMMs).
They can be used with a range of response distributions (e.g. Poisson, Binomial, Gamma).
They can be used in a range of situations where observations are grouped in some way (not all independent).
Fast and can be extended to handle somewhat more complex situations (e.g. zero-inflated Poisson).
Cons
Some of the standard ways we’ve learned to test models don’t apply.
Greater risk of making ‘sensible’ models that are too complex for our data to support.
Note: GLMMs are still under active development by statisticians so not all the answers are know (even by the experts working on them).
18.2.3 Assumptions
18.2.3.1 Pause and think
Based on the assumptions for the previous models we’ve considered in this course, what do you think the assumptions for GLMMs will be?
18.2.3.2 The assumptions for GLMMs
Our units/subjects are independent, even through observations within each subject are taken not to to be. (Replace subjects with ‘groups’, same idea.)
Random effects come from a normal distribution.
The random effects errors and within-unit residual errors have constant variance. I.e., Are variances of data (transformed by the link function) homogeneous across categories?
The chosen link function is appropriate / the model is correctly specified.

18.2.4 Example: Bacteria in blood samples 🦠💉
# Data comes from the MASS package
data(bacteria, package='MASS')
head(bacteria)## y ap hilo week ID trt
## 1 y p hi 0 X01 placebo
## 2 y p hi 2 X01 placebo
## 3 y p hi 4 X01 placebo
## 4 y p hi 11 X01 placebo
## 5 y a hi 0 X02 drug+
## 6 y a hi 2 X02 drug+yis presence or absence of a certain bacteria in a blood sampleIDis the subject the sample came fromaprepresents the treatment variable, with levels ‘p’ for placebo and ‘a’ for active.week, either 0, 2, 4, 6, or 11 indicates the number of weeks since the first test.
The question: does the treatment reduce the probability of bacteria in the sample?
The complication: data are not independent. Some people are more susceptible to bacteria/infection than others.
18.2.4.1 Bacteria model
\[\begin{align*} Y_{it} \sim & \text{Bernoulli}(\rho_{it})\\ \text{logit}(\rho_{it}) = & \mu + X_{it} \beta + U_i\\ U_i \sim & \text{N}(0, \sigma^2) \end{align*}\]- \(Y_{it}\) is presence of bacteria in individual \(i\) at time \(t\)
- \(X_{it}\) has indicator variables for week and treatment type.
- \(U_i\) is an individual-level random effect.
- \(U_i > 0\) if \(i\) is more likely than the average to have the bacteria (allows for within-individual dependence)
This is a Generalized Linear Mixed Model (GLMM)
18.2.5 Inference for GLMMs
We know the probabilities of the \(Y_{it}\) conditional on the random effects:
\[pr(Y_{it} | U_i;\mu,\beta) = \frac{\exp(X_{it} + U_i)}{1+\exp(X_{it} + U_i)}\]
If we knew the \(U_i\), maximize the above to estimate \(\hat\beta\)
Integrate out the unknown \(U_i\)! \[ pr(Y;\mu,\beta,\sigma) = \int pr(Y | U; \mu,\beta) pr(U;\sigma) dU \]writing \(U =[U_1 \ldots U_N]\)
Maximize the above to get \(\hat\mu\), \(\hat\beta\), \(\hat{\theta}\)
Plug-in parameter MLEs when predicting \(U_i\)
\[ \text{E}(U_i |Y; \hat{\mu},\hat{\beta}, \hat{\sigma}) \]
18.2.6 Problems with Likelihood that affect our inference for GLMMs
~10 years ago
We couldn’t evaluate the likelihood, let alone maximize it.
There were approximate methods which get around this:
- Generalized Estimating Equations
- Penalized Quasi-likelihood
- Hierarchical Likelihood (Lee and Nelder)
They could provide good parameter estimates and standard errors for the \(\beta\) but could be poor at finding \(\text{var}(U_i | Y)\).
Packages:
proc glmixin SAS,glmmPQLin R.
Today
Frequentist methods were later to arrive than Bayesian ones, but now they’re here:
- Laplace approximations,
- importance sampling, and
- automatic differentiation.
Packages:
lme4,glmmTMB,prevmap
18.2.7 Back to the bacteria
# How many children?
length(unique(bacteria$ID))## [1] 50# How many weeks?
table(bacteria$week)##
## 0 2 4 6 11
## 50 44 42 40 44# Were all children tested each week?
table(bacteria$week)/50##
## 0 2 4 6 11
## 1.00 0.88 0.84 0.80 0.88# How many in each group?
bacteria %>%
group_by(ID) %>%
slice(1) %>%
group_by(ap) %>%
summarise(n = n())## # A tibble: 2 × 2
## ap n
## <fct> <int>
## 1 a 29
## 2 p 2118.2.7.1 Fitting a model with lme4
Create a new binary variable y:
bacteria$newy = as.integer(bacteria$y=='y')Set treatment variable to placebo for everyone at week zero:
bacteria$ap[bacteria$week == 0] = 'p'Set placebo to be the baseline:
bacteria$ap = fct_relevel(bacteria$ap, "p")Run the model:
#install.packages("lme4")
bRes = lme4::glmer(newy ~ factor(week) + ap + (1 | ID),
family='binomial', data=bacteria)18.2.7.2 Parameter estimates
bRes = lme4::glmer(newy ~ factor(week) + ap + (1 | ID),
family='binomial', data=bacteria)
summary(bRes)## Generalized linear mixed model fit by maximum likelihood (Laplace
## Approximation) [glmerMod]
## Family: binomial ( logit )
## Formula: newy ~ factor(week) + ap + (1 | ID)
## Data: bacteria
##
## AIC BIC logLik deviance df.resid
## 206.1 229.8 -96.0 192.1 213
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.0862 0.1328 0.2736 0.4342 1.2792
##
## Random effects:
## Groups Name Variance Std.Dev.
## ID (Intercept) 1.656 1.287
## Number of obs: 220, groups: ID, 50
##
## Fixed effects:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.7988 0.6265 4.468 7.91e-06 ***
## factor(week)2 0.9561 0.8634 1.107 0.2682
## factor(week)4 -0.6407 0.7586 -0.845 0.3983
## factor(week)6 -0.7644 0.7648 -0.999 0.3176
## factor(week)11 -0.7834 0.7453 -1.051 0.2932
## apa -1.2271 0.6041 -2.031 0.0422 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) fct()2 fct()4 fct()6 fc()11
## factor(wk)2 -0.410
## factor(wk)4 -0.578 0.610
## factor(wk)6 -0.591 0.604 0.706
## factr(wk)11 -0.605 0.612 0.711 0.713
## apa -0.100 -0.471 -0.478 -0.469 -0.462# VarrCorr lets us easily pull out the SD of the random effect
lme4::VarCorr(bRes)## Groups Name Std.Dev.
## ID (Intercept) 1.2867# Let's grad the fixed effects
round(summary(bRes)$coef, digits=2)## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.80 0.63 4.47 0.00
## factor(week)2 0.96 0.86 1.11 0.27
## factor(week)4 -0.64 0.76 -0.84 0.40
## factor(week)6 -0.76 0.76 -1.00 0.32
## factor(week)11 -0.78 0.75 -1.05 0.29
## apa -1.23 0.60 -2.03 0.0418.2.7.3 Confidence intervals
- This takes a long time to run
- …it is computing profile likelihoods so that we can estimate appropriate confidence intervals for our random (
.sig01) and fixed effects.
(bConfint = confint(bRes))## Computing profile confidence intervals ...## 2.5 % 97.5 %
## .sig01 0.5447208 2.27618243
## (Intercept) 1.7222831 4.23051462
## factor(week)2 -0.7149525 2.73645615
## factor(week)4 -2.1956116 0.83274632
## factor(week)6 -2.3382217 0.71406560
## factor(week)11 -2.3220296 0.65311207
## apa -2.5352226 -0.07351393Notice that were are reporting the standard deviation of the random effects, NOT the individual random effect for each person.
18.2.7.4 Aside: Plotting random effects
We focused a lot on the variance and standard deviation of our random effects, but these statistics are are OF something, namely the random effect values for each level of the random effect. We can see the random intercept associated with each subject in the plot below. Sometimes we might be interested in interpreting these values, but usually not as much as our fixed effect.
# ranef() allows us to pull out the random effects
lattice::dotplot(lme4::ranef(bRes, condVar=TRUE)) ## $ID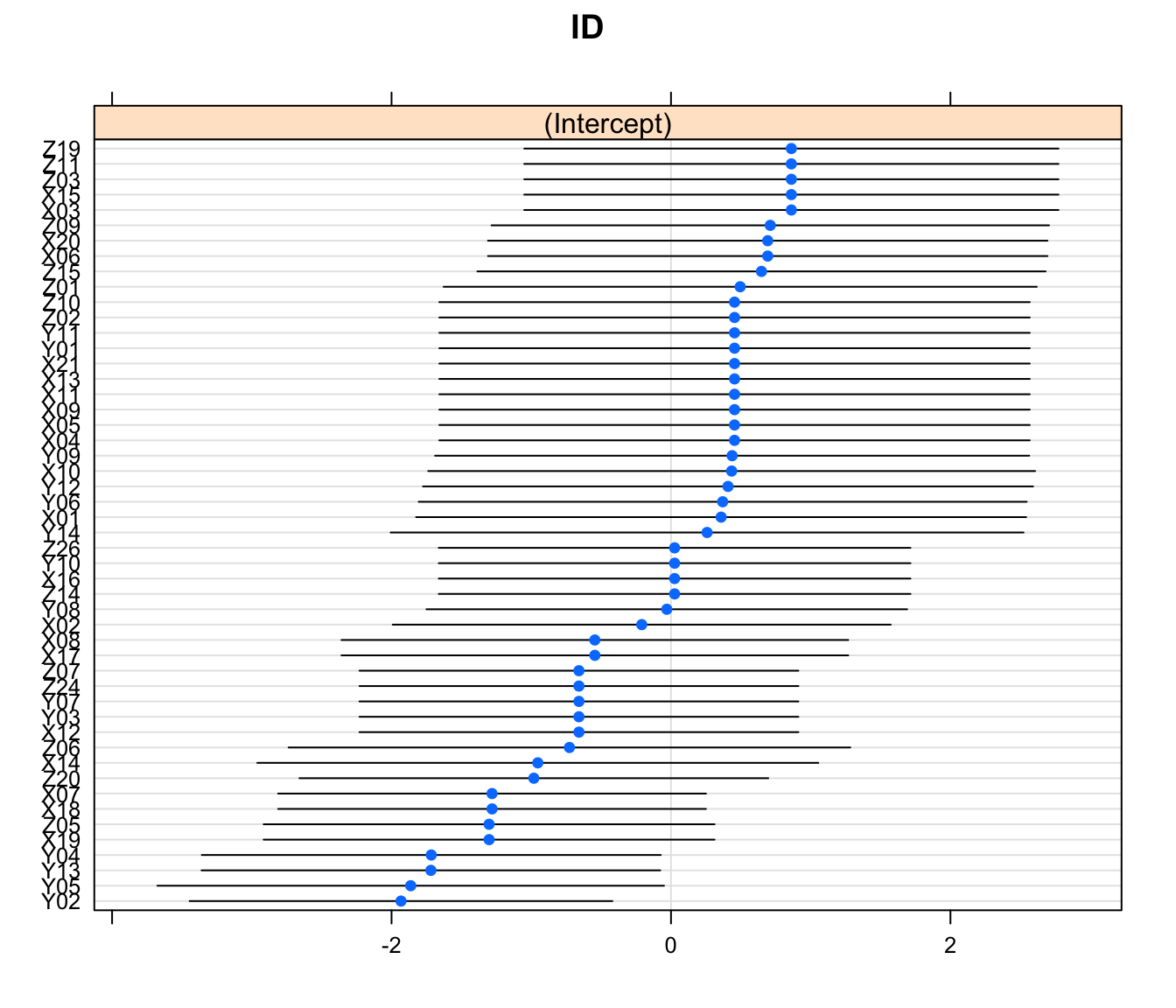
Figure 18.1: Value of the random intercepts for each subject in the bacteria study
18.2.7.5 Prepare a table for reporting
# Get the estimates transformed
ests <- format(round(exp(summary(bRes)$coeff)[,1], 2), nsmall = 2)
ests## (Intercept) factor(week)2 factor(week)4 factor(week)6 factor(week)11
## "16.43" " 2.60" " 0.53" " 0.47" " 0.46"
## apa
## " 0.29"# Get your confidence intervals
cis <- format(round(exp(bConfint),2)[-1,], nsmall = 2)
cis## 2.5 % 97.5 %
## (Intercept) " 5.60" "68.75"
## factor(week)2 " 0.49" "15.43"
## factor(week)4 " 0.11" " 2.30"
## factor(week)6 " 0.10" " 2.04"
## factor(week)11 " 0.10" " 1.92"
## apa " 0.08" " 0.93"## But make it even prettier
cis_pretty <- str_c("(", trimws(cis[,1]), ", ", cis[,2], ")")
cis_pretty## [1] "(5.60, 68.75)" "(0.49, 15.43)" "(0.11, 2.30)" "(0.10, 2.04)"
## [5] "(0.10, 1.92)" "(0.08, 0.93)"# What are the nice names for the rows and columns?
rownames_for_table <- c("Baseline odds", "Week 2", "Week 4", "Week 6", "Week 11", "Active treatment")
colnames_for_table <- c("Estimate", "95% CI")
my_pretty_table <- cbind(ests, cis_pretty)
rownames(my_pretty_table) <- rownames_for_table
colnames(my_pretty_table) <- colnames_for_tableknitr::kable(my_pretty_table, align = c("r", "r"))| Estimate | 95% CI | |
|---|---|---|
| Baseline odds | 16.43 | (5.60, 68.75) |
| Week 2 | 2.60 | (0.49, 15.43) |
| Week 4 | 0.53 | (0.11, 2.30) |
| Week 6 | 0.47 | (0.10, 2.04) |
| Week 11 | 0.46 | (0.10, 1.92) |
| Active treatment | 0.29 | (0.08, 0.93) |
18.2.7.6 Pulling it all together: A short description of the methods (model written out previously)
This study investigates the association between an active treatment and the presence or absence of H. influenzae in children with otitis media in the Northern Territory of Australia. Children were randomly assigned to take either a placebo or drug after the baseline tests at week 0. 50 children were involved in the study (29 in treatment group, 21 in the placebo group) with blood tests conducted at 0, 2, 4, 6 and 11 weeks of treatment. Not all children were tested at all checks, but at least 80% were tested at any given check.
Our outcome of interest was the presence or absence of the bacteria and our predictors were week, treated as a factor, and whether the child was in that active treatment or placebo group. As there were repeated measures for each child, a generalized linear mixed model with logit link was used and random intercepts were estimated for each child.
Menzies School of Health Research 1999–2000 Annual Report. p.20. http://www.menzies.edu.au/icms_docs/172302_2000_Annual_report.pdf.
18.2.7.7 Pulling it all together: Results
The odds of there being bacteria in a blood sample at week 0 are roughly 16:1. Recall that all children are represented in the baseline as everyone was set as receiving the ‘placebo’ at week 0, i.e., no active treatment before treatment started.
Children receiving the treatment had 71% lower odds (95% confidence interval from 7 to 92% lower odds) of having bacteria present in the subsequent tests. There was no significant change in odds of finding bacteria in a child’s blood test from week to week.
| Estimate | 95% CI | |
|---|---|---|
| Baseline odds | 16.43 | (5.60, 68.75) |
| Week 2 | 2.60 | (0.49, 15.43) |
| Week 4 | 0.53 | (0.11, 2.30) |
| Week 6 | 0.47 | (0.10, 2.04) |
| Week 11 | 0.46 | (0.10, 1.92) |
| Active treatment | 0.29 | (0.08, 0.93) |
18.2.8 Generalized Linear Mixed Models, more generally
\[ \begin{aligned} Y_i \sim &\pi(\lambda_i; \theta)\\ \lambda_i = & h(\eta_i) \\ \eta_i = & \mu + W_i \beta + U_i\\ U \sim & \text{MVN}[0,\Sigma(\theta)] \end{aligned} \]
The bacteria model has
- \(\pi(\eta_i; \theta) = \text{Bernoulli}(\lambda_i)\)
- \(\theta = \sigma\)
- \(\Sigma(\theta) = \sigma^2 I\)
- \(h(x) = \log(x)\)
The dimension of \(U\) and sometimes \(\beta\) is very large,
Whereas typically the number of elements in \(\theta\) is small.
(MVN is multivariate normal)
18.2.9 Some key conclusions
- GLMMs are easy to fit (thanks to Taylor series/Gaussian approximations, which we’re not covering here)
- Interpreting GLMMs is similar to interpreting GLMs; we need to be thoughtful as link function makes interpretation subtle at times.
- Personal preference dictates whether to use
glmmTMBorlme4::glmer. glmmTMBis faster on large datasets, but I findlme4approachable for beginners.- Be Bayesian if you wish, but Frequentist GLMMs are a feasible and convenient option.
18.2.10 GLMM Reading
Reading: Chapter 11 of Roback, P. & Legler, J. Beyond Multiple Linear Regression. (2021). https://bookdown.org/roback/bookdown-BeyondMLR/.
This is a really interesting study that looks to update evidence from 2004/2005 that found that referees appeared to be ‘evening out’ foul calls across NCAA men’s college basketball games. It also expands upon the original logistic regression that was applied to attempt to account for additional correlations in the data.
18.3 Case control studies and conditional logistic regression (OPTIONAL)
Based on what we’re focusing on this semester, I am making the content about case control studies and conditional logistic regression optional.
If you’re interested in this, you can check out the 28 minute video from last year, but it won’t be assessed.
18.4 GAMs
The models you’re probably most familiar with at this point in your statistics education, namely those from courses like STA302 and 303, are on one of an interpretability continuum. We can (with some statistics training) interpret what the coefficients for linear regression mean about our data and make inferences in well understood ways. They aren’t the most flexible of models though. On the other side, there are our ‘black-box’ machine learning methods. These can be incredibly flexible and valuable tools for prediction, but in many cases difficult, if not impossible to interpret.
Generalized additive models (or GAMs) are a form of non-parametric modelling that allow us some of the flexibility of machine learning and some of the interpretability of our classic statistical methods.
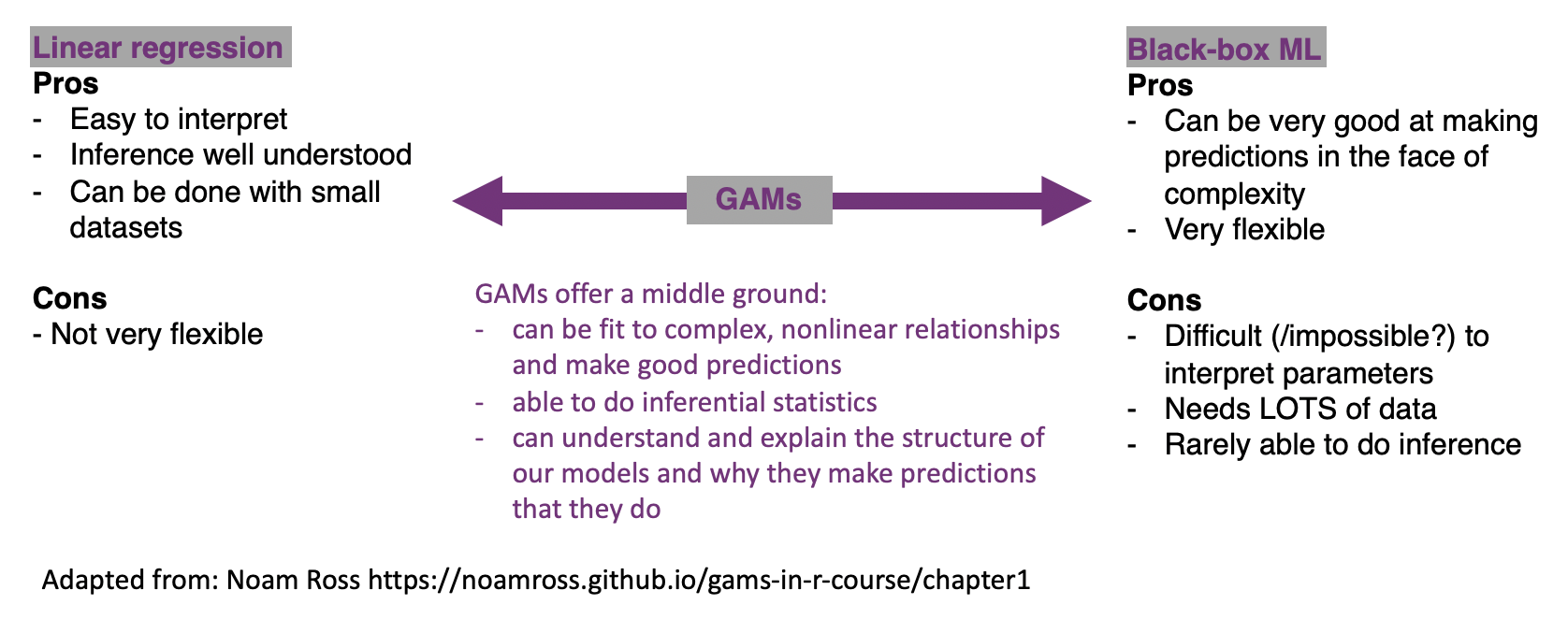
You might also see the following discussed in relation to this class of models:
- Penalized likelihood
- Smoothing
- Fitting wiggly lines through points
- Semi-parametric models
- Splines
18.4.1 A one tweet GAM lesson
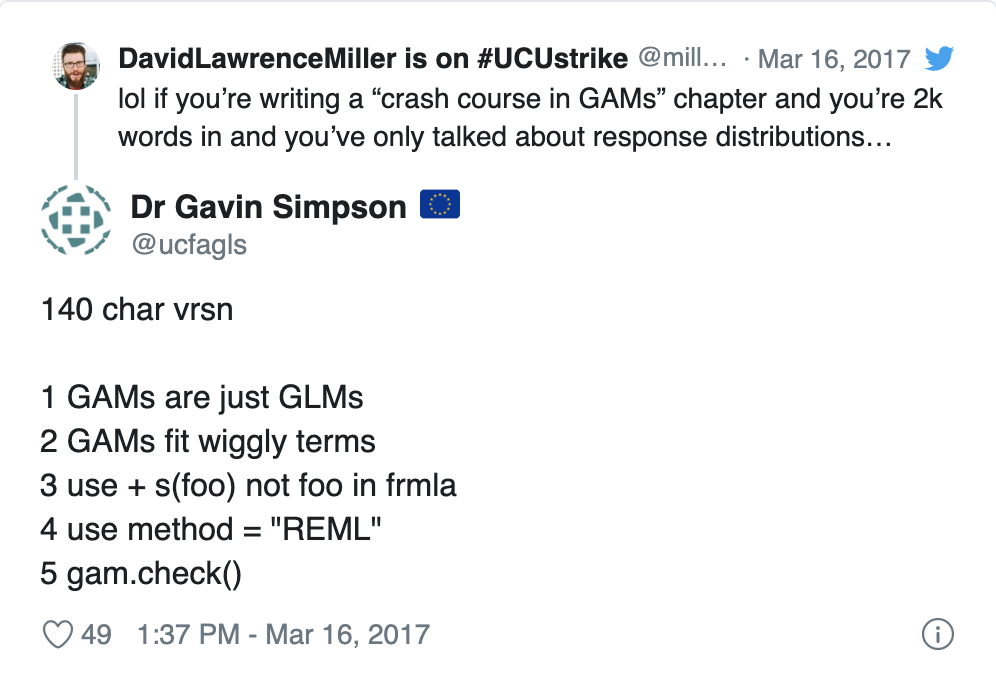
https://twitter.com/ucfagls/status/842444686513991680?ref_src=twsrc%5Etfw
18.4.3 Linear model?
p + geom_smooth(method="lm")## `geom_smooth()` using formula 'y ~ x'## `geom_smooth()` using formula 'y ~ x'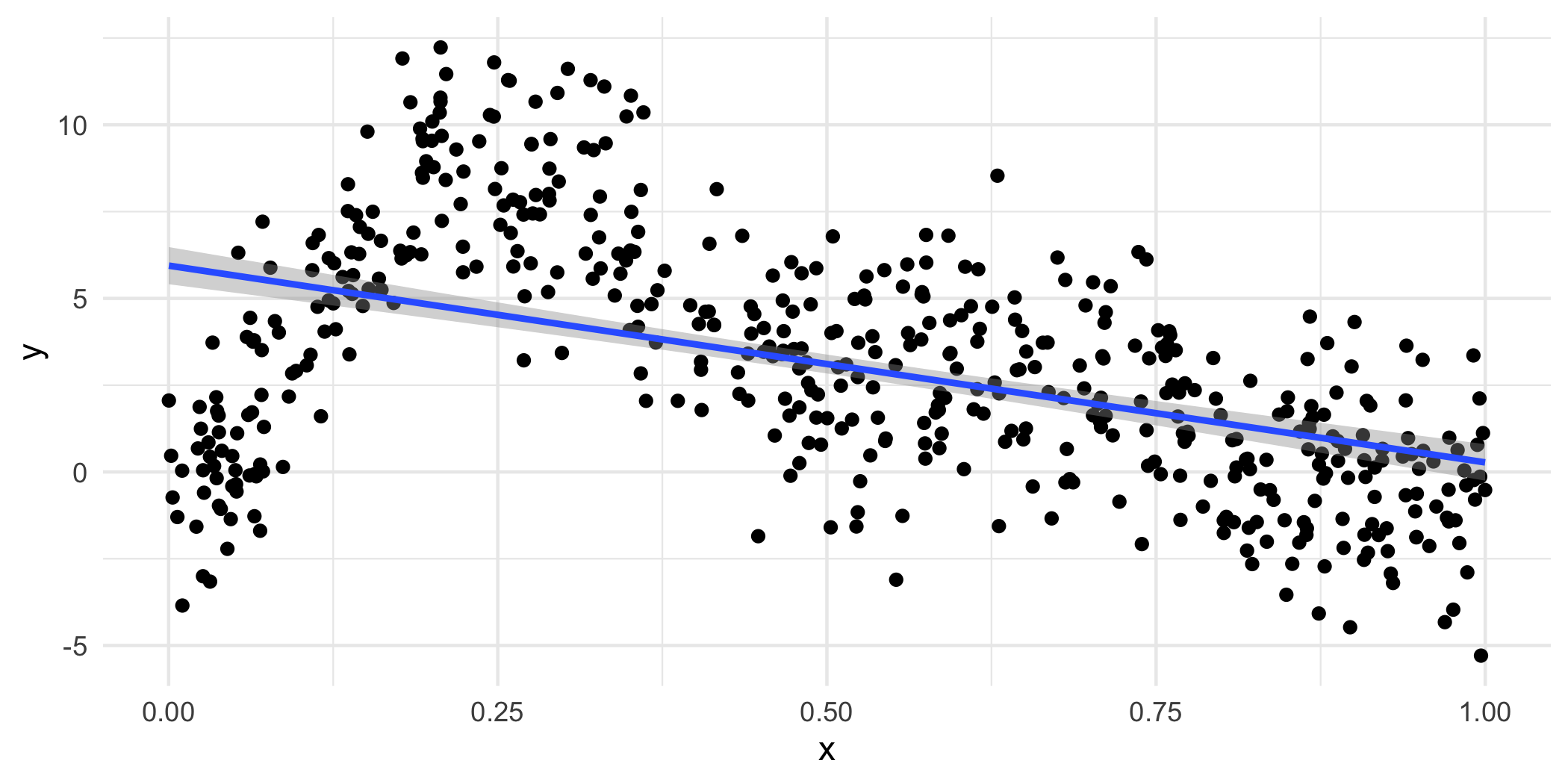
Well, that seems bad…
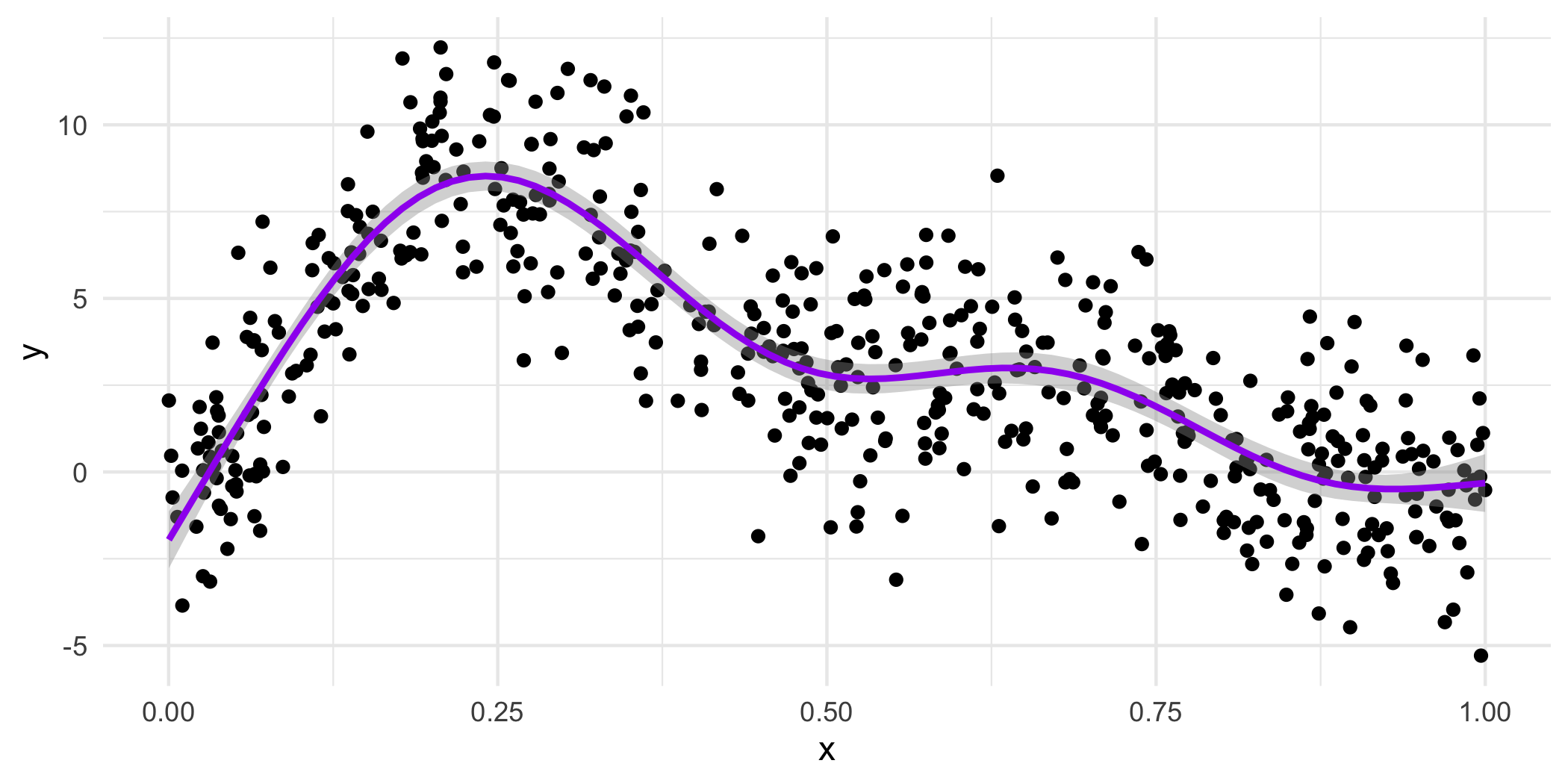

18.4.4 How do we get the wiggles?
Answer: Splines!
If you’ve looked at interference of waves in physics, you’ll love this. If you haven’t….you’ll also love this!

GAMs are both smooth and flexible thanks to actually being made up of multiple not-as-flexible functions. Imagine the Power Rangers robot teaching you a yoga class.
- Each smooth is the sum of a number of basis functions
- Each basis function is multiplied by a coefficient
- Each of those coefficients is a parameter of our model
18.4.5 Splines
- Splines are functions composed of simpler functions
- Our simpler functions are basis functions & the set of basis functions is a basis
- When we model using splines, each basis function \(b_k\) has a coefficient \(\beta_k\)
- The resulting spline is the sum of these weighted basis functions, evaluated at the values of \(x\)
\[s(x) = \sum_{k = 1}^K \beta_k b_k(x)\]
18.4.6 Picturing basis functions
- Plot a shows the basis functions of a GAM where all the coefficients are the same.
- Plot b shows the same basis functions after model-fitting, where each has a coefficient fit to the data.
- Basis functions add up to create the overall smooth shape.
Describing this one, nonlinear relationship (one response and one explanatory variable) requires several parameters, plus an intercept.
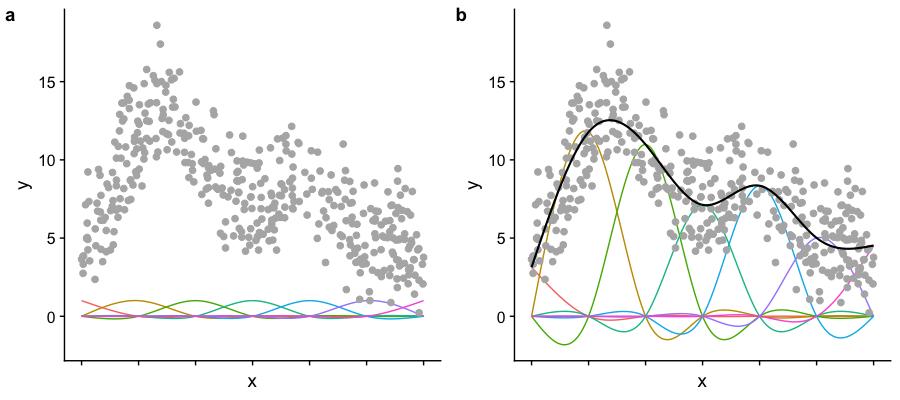
Image created by Noam Ross.
18.4.7 Wiggle, wiggle, wiggle

GIF by Gavin Simpson
18.4.7.1 Taking a peak at our coefficients
library(mgcv) # you will need to install this
gam_mod <- gam(y ~ s(x, k=7), data=my_data, method="REML")
coef(gam_mod)## (Intercept) s(x).1 s(x).2 s(x).3 s(x).4 s(x).5
## 3.074352 -10.512816 14.800850 -5.780337 -3.959907 18.597941
## s(x).6
## 10.047384This is just some meaningless fake data, we’ll work through a Case Study more fully.
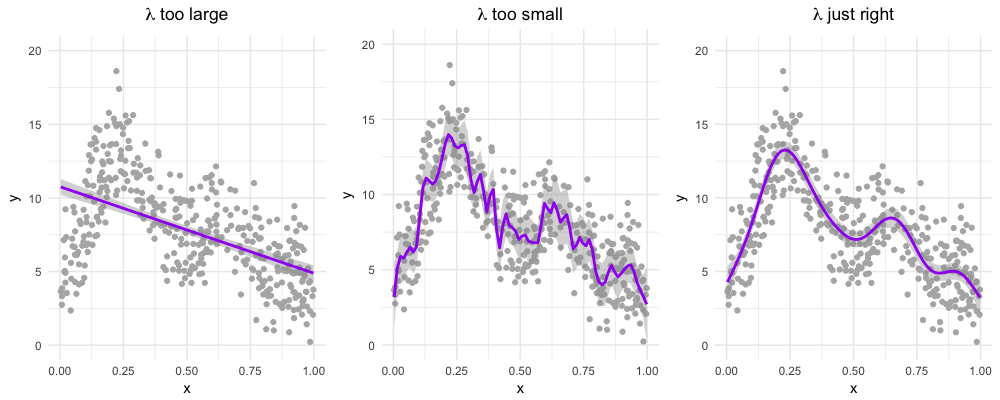
{kind=link}
{kind=link}
{kind=link}
18.4.7.4 Smoothing
You can think of our fit as being:
\[\text{penalized log lik} =\log(\text{Likelihood}) - \lambda \cdot \text{Wiggliness}\]
where \(\lambda\) is a smoothing parameter.
We can set lambda with the sp (smoothing parameter) option in gam() BUT it is recommended that we let R find the best one for us using restricted maximum likelihood (“REML”).
# Sets parameter for the whole model
gam_mod <- gam(y ~ s(x), data=my_data, sp=0.1)
# Set the parameter for one specific term
gam_mod <- gam(y ~ s(x1, sp=0.1) + s(x2), data=my_data)
# Let R do it for you - the recommended way
gam_mod <- gam(y ~ s(x), data=my_data, method = "REML")18.4.8 Choices to make
18.4.8.1 Wiggliness
There are LOTS of ways to pick your wiggle: AIC, generalized cross-validation (GCV, part of the name of mgcv and the default for that package), ML and REML.
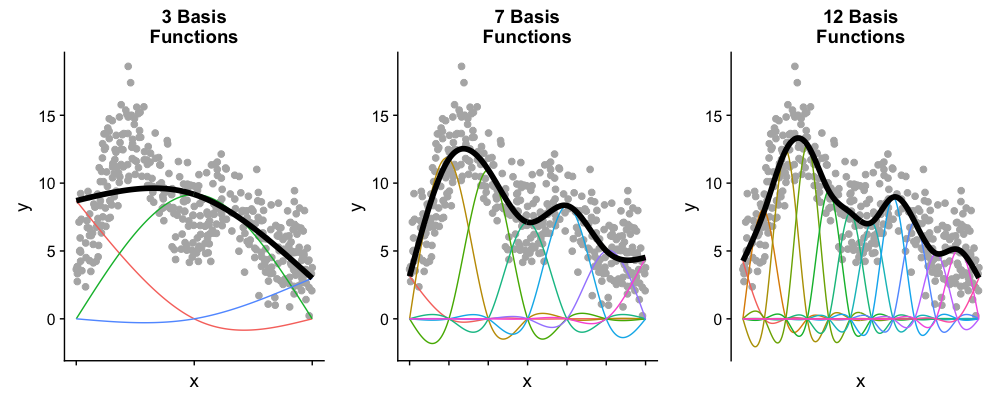
18.4.8.2 Basis complexity
We can set a maximum wiggliness by setting a ‘size’, k, that indicates a maximum number of small functions that could be used to build the model. If we set it bigger than the data, we’ll get an error, and if we set it much bigger than needed, it is computationally costly.
Our effective degrees of freedom (edf) will always be less than k. We can check if we’ve been sensible in our choice of k with gam.check().
18.4.8.3 Basis expansions
In the polynomial models we used a polynomial basis expansion of \(\boldsymbol{x}\)
- \(\boldsymbol{x}^0 = \boldsymbol{1}\) — the model constant term
- \(\boldsymbol{x}^1 = \boldsymbol{x}\) — linear term
- \(\boldsymbol{x}^2\)
- \(\boldsymbol{x}^3\)
- …
So! If the effective degrees of freedom we need for a term is approximately 1, then we’re really just smoothing it down to a linear term, the way a covariate would usually enter a model as a fixed effect in our previous models. We may choose to just put it in the model as such, so that we can interpret the coefficient it receives.
18.4.9 Generalized additive (mixed) models
We can combine everything we’ve done in this course so far into generalized additive models (including adding random effects).
\[\begin{align*} Y_i \sim & G(\mu_i, \theta)\\ g(\mu_i) = & X_i \beta + Z_iU + f(W_i) \end{align*}\]- \(Y_i\) are responses
- \(G\) is the response distribution
- \(X_i\), \(Z_i\) and \(W_i\) are covariates
- \(U\) are our random effects
- \(f(w)\) is some sort of wiggly line
- If we put no restrictions or assumptions on \(f\), the estimate \(\hat f(w)\) will interpolate the data perfectly (which isn’t very interesting)
Random effects
When fitted with REML or ML, smooths can be viewed as just fancy random effects. AND, excitingly, random effects can be viewed as smooths!
If your random effects are fairly simple, you can fit those in mgcv::gam() without needing the more complex GAMM functions, like gamm4::gamm4()
These two models are equivalent:
# library(mgcv)
# You don't need to know anything about this data,
# just consider how that variables enter the models
m_nlme <- lme4::lmer(travel ~ 1 + (1 | Rail), data = Rail, REML = TRUE)
m_gam <- gam(travel ~ s(Rail, bs = "re"), data = Rail, method = "REML")18.4.10 Random effects
The random effect basis, bs = 're', is not as computationally efficient as lme4 if we have complex random effects terms or even if we just have random effects with many levels (which isn’t really that unusual with random effects).
Instead we could use gamm() or gamm4::gamm4():
gamm()fits usinglme()gamm4::gamm4()fits usinglmer()orglmer()
I.e., you’re wanting a response with a conditional distribution that isn’t normal, use gamm4::gamm4()
18.4.11 Case studies: Cherry trees and Portugese larks
18.4.11.1 Access the code for the case studies
You can pull the code on to the JupyterHub with this
link.
From your Home directory, you will need to navigate to
sta303-w22-activities -> m5.
18.4.12 Further comments on GAMs
18.4.12.1 GAMs are models too
How accurate your predictions are depends on how good the model is, as always. (Credit: Eric Pedersen & Gavin Simpson)

18.4.12.2 Variable selection
Unmodified smoothness selection by GCV, AIC, REML etc. will not usually remove a smooth from a model (not set edf to 0). Most smoothing penalties view the null-space of a smooth as ‘completely smooth’ and so further penalization does not change it.
With select = TRUE we add an extra penalty to the null-space part (the part of the spline that is perfectly smooth).
If you don’t have this, smoothness selection can usually only penalize a smooth back to a linear function
(because the penalty that’s doing smoothness selection only works on the non-smooth (the wiggly) parts of the basis). To perform selection we need to be able to penalize the null space (the smooth parts of the basis) as well.
18.4.12.3 Smoothness selection
The method argument to gam selects the smoothness selection criterion. For many practitioners, ‘ML’ or ‘REML’ are their default choice, though not the default in gam(). Using a likelihood based approach essentially treats the smooth components as random effects.
18.4.12.4 More conditional distributions than you can shake a squiggly line at
A GAM is just a fancy GLM! So we can fit any of the models we’ve learned (Poisson, Logistic, Gamma as we saw today in the cherry example). The creators of the mgcv package (Simon Wood & colleagues (2016)) have extended the methods to some non-exponential family distributions that are also very helpful, of which we’ve seen Negative Binomial and Zero-inflated Poisson.
binomial()poisson()Gamma()inverse.gaussian()nb()tw()mvn()multinom()betar()scat()gaulss()ziplss()twlss()cox.ph()gamals()ocat()
18.4.12.5 A symphony of smoothers
The type of smoother is controlled by the bs argument (think basis)
The default is a low-rank thin plate spline bs = 'tp'
Many others available (thanks Gavin Simpson for making this list):
- Cubic splines
bs = 'cr' - P splines
bs = 'ps' - Cyclic splines
bs = 'cc'orbs = 'cp' - Adaptive splines
bs = 'ad' - Random effect
bs = 're' - Factor smooths
bs = 'fs' - Duchon splines
bs = 'ds' - Spline on the sphere
bs = 'sos' - MRFs
bs = 'mrf' - Soap-film smooth
bs = 'so' - Gaussian process
bs = 'gp'
18.4.12.6 How do we talk about GAMs?
Presenting results from GAMs is similar to presenting results from other models we’ve learned except that for smoothed terms we have no single coefficient you can make inference from (i.e. negative, positive, effect size etc.).
For smoothed variables, we rely a lot on visual methods (e.g. plot(gam_model)) for describing our results and we can also make inference from predicted values.
For parametric variables, we can make inferences like we normally would.
GAMs are especially useful for accounting for a non-linear phenomenon that may not be the main thing you are interested in. This is similar to how we have already used random effects to account for correlation in our data that is not the main thing of interest but shouldn’t be ignored.